

The evolution of AI (artificial intelligence) technology is remarkable, especially in the field of natural language processing. The impetus for this development was the emergence of a deep learning model for natural language processing called “Transformer.”
Transformer is also the basis of the ChatGPT model developed by OpenAI, and the T in GPT in ChatGPT is an abbreviation for Transformer.
Transformer is the foundation of language understanding and generation technology for the services and products we use. It can be said to be a necessary model for understanding generative AI of texts such as ChatGPT and natural language processing. In this article, we will explain in detail the mechanism and features of the Transformer, and explain how it achieves high-performance models.
AI Market selects and introduces development companies that are strong in introducing ChatGPT. You can easily find the best company for your company in a few days. We can introduce you to multiple companies that can meet your company’s needs, and you can quickly make competitive estimates and comparisons.
Transformer is a deep learning model for natural language processing, designed around a technology called “Attention.” This is a model related to natural language processing that appeared in a paper published by Google researchers in 2017 called “Attention is All You Need.”
It is a neural network for series transformation models. A sequence is an ordered sequence, and sequence conversion refers to converting one sequence to another. Since a sentence can be said to be a sequence of words, it can be used for a wide variety of natural language processing tasks.
How are transformers working?
Since the early 2000s, neural networks have been the major approach to training on the various sets of tasks in AI, including image recognition and Natural language processing. The vital part of these networks consists of numerous layers of linked-up nodes or neurons that closely mimic the human brain in their ability to process and cooperate in solving complex problems.
Traditional neural networks dealing with sequence data usually utilize one encoder-decoder architecture. The encoder reads the entire input sequence, such as an English sentence, and processes it into a compact mathematical summary that merely captures the input. This summary is passed to the decoder, which generates the output sequence one step at a time.
This sequentially processes the data as words or parts of the data, most of the time wasting time and sometimes losing finer details with long sequences.
Self-attention mechanism
Transformers fix this through a mechanism called self-attention. In place of processing data in a linear timeline, the self-attention mechanism works in such a way that the model scans various parts of the sequence simultaneously and determines which parts are most important.
Here’s an example: think of it being underwater, in a pretty noisy room, listening in on one person. Your brain automatically focuses on your voice while blanking out less important noises. Self-attention makes this model do pretty much the same thing. It automatically weighs the different input values, temporarily emphasizing all the important ones, and then aggregates them to make better predictions. This makes transformers more effective and efficient, especially with long texts where earlier context is really important in understanding later parts.
The Transformer Architecture
Transformer is a neural network that learns context and its meaning by tracking the relationships between continuous data such as words contained in sentences. There are various types of series conversion tasks. For example, in machine translation, you can convert English sentences to Japanese sentences. For summarization tasks, this means converting the original text into a summary sentence.
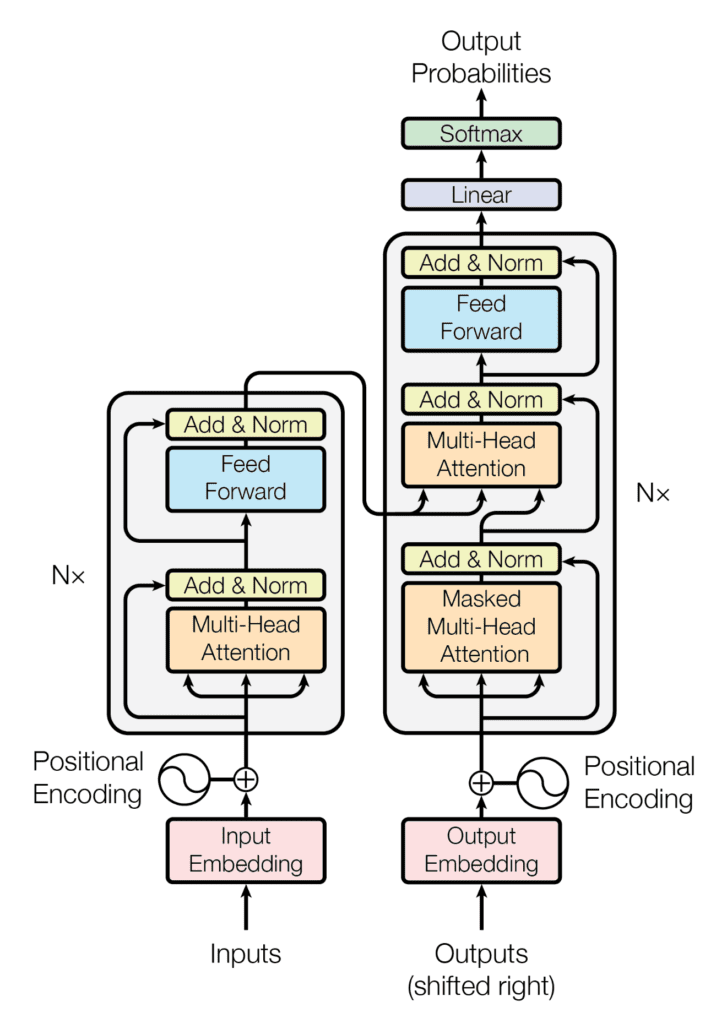
Transformer is made up of two parts, an “encoder” and a “decoder”, to understand sentences. The two are connected in a special way called the Self-Attention mechanism
The Encoder
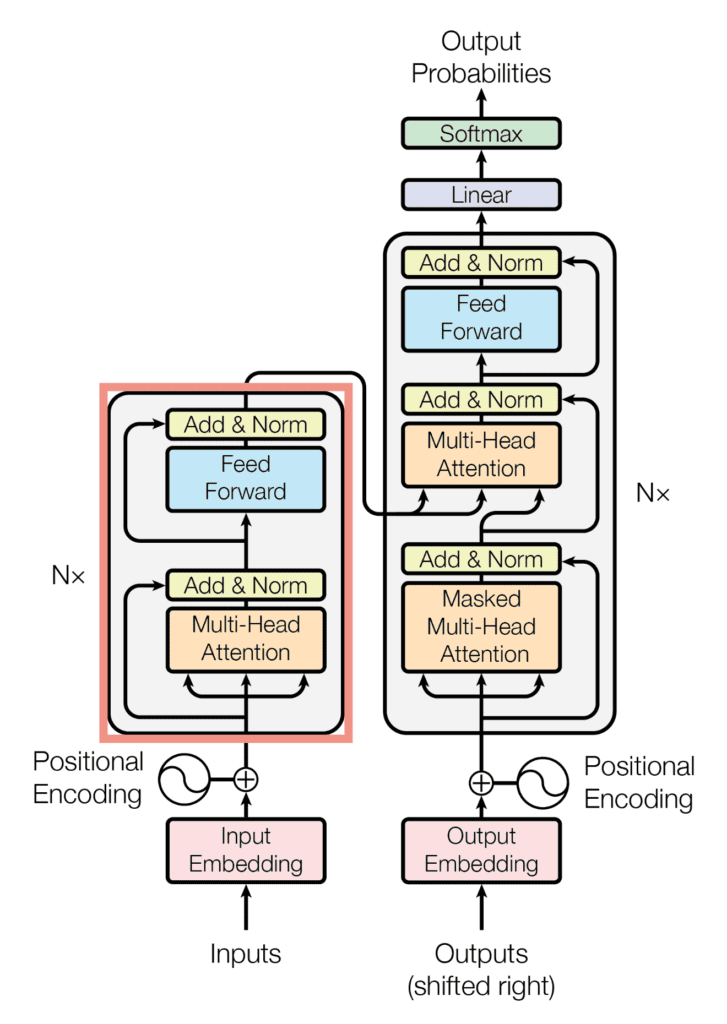
An encoder captures important information and features of input data and composes it into a compact form in a stack of multiple layers. In technical terms, the role of an encoder is to convert input information into a vector, sequence, etc
To put it simply, your role is to read the text and find the important points within it. For example, in the sentence “The dog chases the ball,” the encoder understands that “dog,” “ball,” and “chase” are important words.
The Decoder
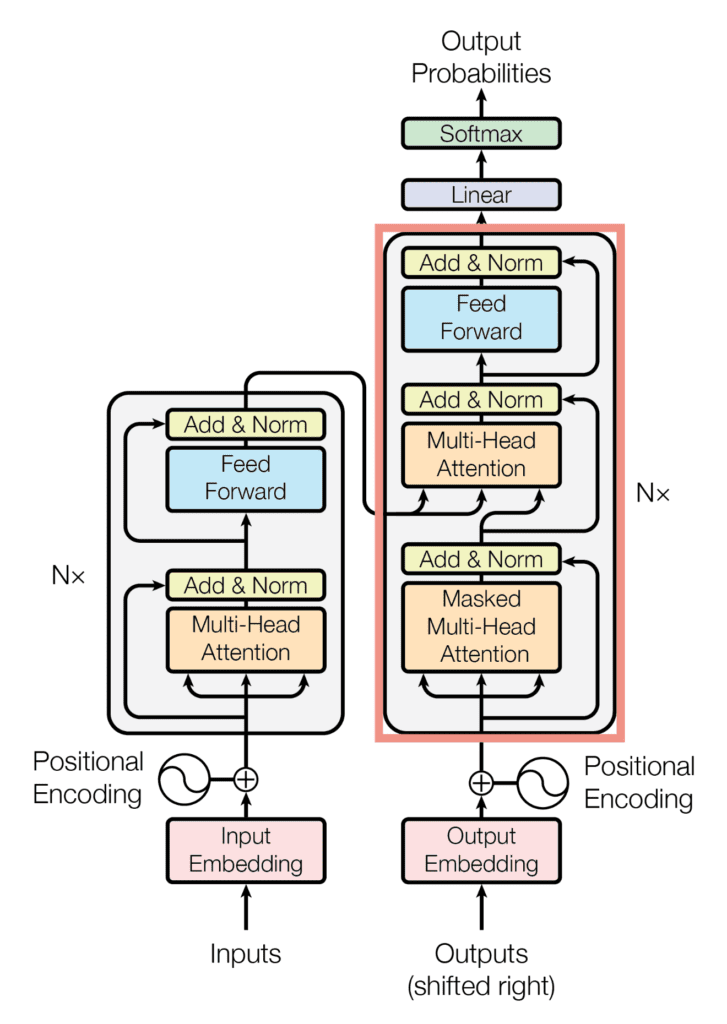
The decoder is to use the important points found by the encoder to generate new data that serves the purpose depending on the processing content. For example, if a question-answering system asks you, “Who will chase the ball?”, you might answer, “The dog will chase it.”
In the paper published by Transformer, there were six encoder and decoder layers. Currently, the number of layers is adjusted as needed.
Attention
Transformer is designed around a mechanism called “Attention”. Attention is a mechanism that determines and focuses on which word is the “most” important information in a given sentence.
Specifically, it weights each word in the input sentence based on its relationship to all other words. Calculate how related and important one word is to another.
For example, in “The dog chases the ball,” “dog” is directly related to “chasing.” Calculate this relationship mathematically to find out which words are most important.
Fully Connected Layer
There are also fully connected layers in the Transformer model. This fully connected layer works to understand the meaning of the text more deeply. A fully connected layer is a layer in a neural network where each node is connected to every other node. Nodes are small parts that receive information and perform simple calculations for the computer to think about. For example, perform simple calculations such as addition and multiplication.
A fully connected layer is a state in which many small “nodes” are tightly connected. Because each node is “fully connected” to all other nodes, information flows very efficiently. This is one of the reasons why computers can solve complex problems.
Inside Transformer’s encoders and decoders, fully connected layers calculate relationships between words and phrases to produce more accurate sentences. Thanks to this layer, translation apps can provide accurate translations, and game AI can move intelligently.
Why are transformers important?
Transformer models demonstrate high performance for many tasks in the field of natural language processing. We have developed the structure of the Transformer and created many derived models
Improve calculation amount and accuracy with attention only
A major feature is that processing can be performed using only Attention, which is the core of Transformer. The attention mechanism is a method that calculates the degree of association of each element between two series.
There are several variations of attention mechanisms, and Transformer employs a feature called “Self-Attention” that simultaneously considers all elements in the sequence and their relationships to all other elements.
By learning only with the attention layer without using conventional convolutional layers, it is possible to perform high-speed and highly accurate processing.
Parallel Processing Possible
Transformer is particularly effective in environments where parallel processing is easy and there are many computational resources. Parallelism is the execution of multiple instructions at the same time.
Conventional deep learning models such as RNN and LSTM process processes sequentially. This is a model that recognizes words in a sentence in order, understands their relationships, and predicts what word will come next.
Transformer, on the other hand, can process in parallel, so it can more accurately understand the relationship and context of words in a sentence. Parallel processing allows for faster training, so even large and complex models can be processed efficiently.
Long-term Memory Possible
The advantage of Transformer is that even if data such as long sentences are input, it can be memorized and processed until the end. Conventional RNNs perform sequential processing, which causes the phenomenon of forgetting previous information during processing. Transformer’s long-term memory allows it to process long texts accurately.
AI Market selects and introduces development companies that are strong in introducing ChatGPT. You can easily find the best company for your company in a few days. We can introduce you to multiple companies that can meet your company’s needs, and you can quickly make competitive estimates and comparisons.
A professional AI consultant will select several companies on your behalf, so if you are unsure about choosing a development company or don’t know how to consult, please feel free to contact AI Market, which has over 1,000 consultations in total. please.
What can transformers be used for?
You can train big transformer models on any type of sequential data like human languages, music programming languages, and more. Here are some example uses:
Natural language processing
Transformers make computers value, understand, and generate a human-like language in ways that have never been witnessed before. They can condense long pieces and even write related and coherent text for other uses. Transformers are behind virtual assistants like Alexa understanding and responding to voice commands.
Machine translation
When dealing with translation tools, transformers have enabled real-time translations among different languages with precision. The fluency of translation has increased by far with transformers compared to the previous strategies that were used in translation.
DNA sequence analysis
By representing segments of DNA as a series of languages, the transformers can anticipate genetic mutations’ effects, discern genetic patterns, and recognize parts of DNA associated with specific diseases; the essence of personalized medicine where the treatment of an individual is enhanced by the knowledge of his/her genes.
Proteins structure analysis
Sequence is all transformers are great at, and so, long chains of amino acids that fold into complex protein structures seemed like a natural fit. Scientists would love to understand such structures since that can aid drug discovery and the study of many biological processes. And now, transformers can do what scientists would love: predicting the 3D structure of proteins from their amino acid sequences is possible thanks to transformers.
What are the different types of transformer models?
Transformers have grown into different types of architecture. Some of the types of transformer models are listed below:
Bidirectional transformers
Bidirectional encoder representations from transformers, or BERT, models alter the original architecture to read the words about all the other words that are there in a sentence, rather than sequentially reading each word and relating each word only to itself. It uses a trick called the bidirectional MLM. During pretraining, BERT randomly masks some of the input tokens and predicts these masked tokens based on their context. The bidirectional aspect here is that BERT views both left-to-right and right-to-left token sequences in both layers for better comprehension.
Generative pre-trained transformers
GPT models make use of stacked transformer decoders pre-trained on large text corpus using language modeling goals. They are autoregressive. This means that they predict every word in a given sequence based on all the words that come before it. GPTs have over 175 billion parameters to generate text sequences adjusted for style and tone. GPTs enabled an institutional shift in the direction of AI towards AGI, giving organizations the ability to transcend productivity to new heights while transforming systems of applications and customers’ experiences.
Bidirectional and autoregressive transformers
BART is a bidirectional and autoregressive transformer because it fuses both of these abilities of transformers, combining BERT’s bidirectional encoder and GPT’s autoregressive decoder. So, it reads the input sequence once, as a whole, like BERT. However it generates the output sequence token by token, looking at the generated tokens so far, and the input from the encoder.
In the same line with the multimodal transformer family, there will also be ViLBERT and VisualBERT. However, these models will be set up to handle two different kinds of input data, text and images. The model extends the transformer by dual-stream architectures to handle the inputs separately before fusing the two sources of information. This is done to enable the learning of cross-modal representations. For instance, ViLBERT uses co-attentional transformer layers to let the separate streams interact. This is an export of crucial tasks, for instance in recipe-text-image pairing tasks where the relationship between the text and image needs to be understood.
Vision Transformers
Vision transformers are a modification of the transformer architecture used for image classification tasks. Instead of processing an image as a grid of pixels, they treat the data in the image as a sequence of fixed-sized patches, just as words in a sentence. All patches are first flattened, linearly embedded, and then sequentially passed to the standard Transformer encoder. During this process, positional embeddings are added to hold spatial information. This kind of global self-attention allows the model to relate any patch to any other patch, regardless of its relative position.
Conclusion
The transformers have evolved now into a wide family of models that can achieve a variety of tasks. Starting from BERT’s dealing with text in a bidirectional manner to better understand it, to GPT’s autoregressive text generation with style and tone, the models have drastically altered the AI playing field. BART brings along the best of both worlds and multi-modal transformers like ViLBERT and VisualBERT can fly through with flying colors those tasks which require a good understanding of both text and images. The results are called vision transformers, working directly on the transformer power for image classification by treating images as sequences of patches. These developments in the models of transformers bring better performance and ability to a range of applications.
FAQ
Q1: What are transformers used for?
A: Transformers have been used for a host of NLP MT DNAA PSA and IC.
Q2: What is BERT?
A: BERT is a type of transformer that reads the words against all other words in a sentence as opposed to just sequentially. It looks at context much better using a bidirectional approach.
Q3: What is GPT?
a) GPT It is generation-based. It predicts one word in a sequence based on all the previous ones. Essentially, millions of parameters allow this model to generate text semantically guided by examples of styles and tones.
b) How are BERT and GPT merged into BART?
A) BART brings together the ability of BERT to read text in both directions with the autoregressive way GPT generates text; hence, it is great for problems that simultaneously require an understanding and creation of text sequences
c) What are multimodal transformers?
A: In line with the same way as those multimodal transformers ViLBERT and VisualBERT that generate the text and the images, then combine the outputs. They are applied in tasks that require text-image relationships.
Q4: vision transformers?
A: In the same way that words in a sentence of fixed size can be considered as a word sequence, vision transformers operate by considering an image as a sequence of fixed-size patches. Global self-attention allows the transformer to learn the relationship between different image patches.